 中国计算机学会芯片大会(CCF Chip 2024)
中国计算机学会芯片大会(CCF Chip 2024)




 首页
首页会议动态 
CCF TCArch 定制计算挑战赛 2024 – 消费级显卡的LLM部署加速
1. 赛题简介
CCF TCARCH- 计算机体系结构挑战赛是中国计算机学会体系结构专委会所举办的旨在挖掘计算机体系结构人才、激发学生对计算机体系结构的研究兴趣、培养学生创新精神的一项全国赛事,是国内体系结构相关优秀学生交流学习的最佳平台之一。赛事于2018年首次举办,已举办5届,2021年开始此赛事的决赛均在CCF体系结构专委所承办的CCFSys/CCFChip大会中举行并进行颁奖典礼,优秀作品论文有机会入选大会论文集。
2. 赛题介绍
近年来,随着大型语言模型(LLM)的兴起,其在自然语言处理任务中的应用已成为人工智能领域的热点。同时MLC LLM, llama.cpp等项目的出现,旨在提高LLM在消费级显卡甚至个人计算机上的推理速度,降低了大模型部署对硬件资源的需求,使更多人从大模型中获益。例如在CMU 陈天奇团队MLC项目的测试(使用4 bit量化对Llama 2 7B和13B,设置prompt长度为1个token,生成512个 token来测量decoding的性能,batch size=1):

可以看到在MLC LLM项目中, 不管是Nvidia RTX 还是AMD Radeon 消费级显卡都取得了很不错的推理速度。而llama.cpp是一个相对早期的LLM推理引擎开源项目,其架构设计可以通过CPU/GPU进行混合加速推理任务,甚至可以仅依靠CPU完成推理。然而,随着LLM规模的增大和任务的复杂性,llama.cpp在处理大规模模型时面临内存需求和计算效率方面的挑战。
上海交大IPADS 实验室在2023年12月发布了PowerInfer开源项目,其在llama.cpp基础上采用了一种全新的设计思路,利用LLM推理中的高局部性特征。该局部性具体表现为神经元激活的幂律分布,即少数“热”神经元在不同输入下保持激活,而大多数“冷”神经元根据具体输入变化。PowerInfer充分利用了这一特点,设计了一种GPU-CPU混合推理引擎,通过将热激活的神经元预加载到GPU中,而将冷激活的神经元计算在CPU上,从而显著降低了GPU内存需求和CPU-GPU数据传输。目前该项目也已经在llama2-7B模型上实现了Nvidia和AMD GPU的支持。
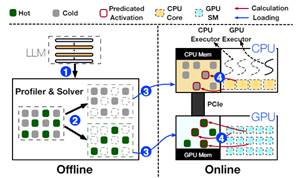
本次比赛,可参考PowerInfer的开源项目,要求参赛队在熟悉Llama2-7B的优化方法基础上,利用开源的ROCm开源堆栈和HIP编程模型在Radeon 7900XTX GPU上对7B/13B模型: Bamboo-7B/Prosparse-13B展开优化,方法不限(例如算子优化、混合精度量化等)。
3. 赛题评分
本赛题的评分主要包含两个部分,为推理速度和推理模型精度。其中推理速度评分占比70%,模型精度占比30%。
3.1推理速度:推理速度分为prompt处理速度和token生成速度。Prompt处理速度:是指模型接收输入的prompt(提示)并处理所有输入token,直到生成第一个输出token所需的时间,即Prefill速度。Token生成速度:是指模型在生成第一个输出token之后,继续生成后续token的速度,即Decode速度。本赛题采用生成128个token的平均速度作为decode速度。
本赛题采用指标tokens/s,在给定prompt中,推理速度越快越好。本赛题分别以参赛者最快运行时间Decodebest、Prefillbest为基准,推理生成速度评判分数计算如下:
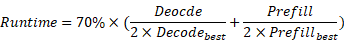
3.2模型精度的评估指标如下:本赛题使用困惑度(PPL)作为模型精度的评估指标,以模型在给定语料困惑度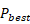 为基准,模型精度评估分数计算如下:
为基准,模型精度评估分数计算如下:
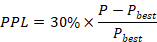
综合两者评分即为总分:
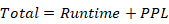
4. 赛事组织
主办单位:中国计算机学会体系结构专委会
承办单位: CCFChip竞赛组委会
5. 报名
报名:请点击以下链接或扫描二维码报名组委会将根据报名信息通知培训时间

https://www.wjx.top/vm/mBrTh1g.aspx
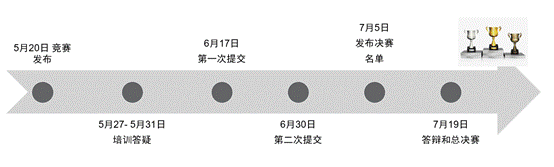
6. 比赛日程
7. 奖项与奖金
第一名 10,000元
第二名 5,000元
第三名 3,000元
优秀作品将有机会入选CCFChip大会论文集
证书:成绩前10% 一等奖证书,11- 25%, 二等奖证书,26%-40% 三等奖证书
8. 比赛咨询:
CCC_CCF@outlook.com或报名后加入群组讨论
挑战赛详情: https://ccf-tcarch-ccc.github.io/2024/
参考资料
[1] Llama.cpp
[2] PowerInfer